 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstimating Mutual Information between Time Series and Temporal Event Sequences Across Diverse Analysis Tasks
Jun 01, 2026Pairwise dependence measures such as correlation and causality are fundamental to temporal data mining, yet there is still no principled and robust way to quantify dependence between heterogeneous data types, especially between continuous time series and discrete temporal event sequences. Existing approaches rely on ad hoc transformations or mutual-information estimators that are highly sensitive to quantization, repeated values, and event redundancy, leading to biased or unstable results in practice. We propose a nonparametric mutual information estimator that directly measures the dependence between time series and event sequences without data transformation, learning, or ad hoc discretization. Our method models the continuous-discrete duality of real-world time series to handle quantization and repeated-value artifacts and introduces a latent event clustering strategy to mitigate bias from event co-occurrence and redundancy. Together, these yield a robust and unified framework that bridges discrete and continuous mutual information. We evaluate the proposed estimator on four representative tasks: discrete-continuous time-delayed mutual information for causality analysis, global and local temporal repetition discovery, discrete covariate selection for time series forecasting, and continuous feature selection for classification. Experiments on synthetic and real-world datasets show consistent improvements over existing methods in accuracy, robustness, and interpretability, positioning our approach as a general-purpose dependence operator for heterogeneous temporal data, similar to Pearson correlation for homogeneous time series. Code available at: https://github.com/HaojiHu/Multimodal-Temporal-Data-Quantification
NARA: Anchor-Conditioned Relation-Aware Contextualization of Heterogeneous Geoentities
May 12, 2026Geospatial foundation models have primarily focused on raster data such as satellite imagery, where self-supervised learning has been widely studied. Vector geospatial data instead represent the world as discrete geoentities with explicit geometry, semantics, and structured spatial relations, including metric proximity and topological relationships. These relations jointly determine how entities interact within space, yet existing representation learning methods remain fragmented, often restricted to specific geometry types or partial spatial relations, limiting their ability to capture unified spatial context across heterogeneous geoentities. We propose NARA (Neural Anchor-conditioned Relation-Aware representation learning), a self-supervised framework for vector geoentities. NARA learns context-dependent representations by jointly modeling semantics, geometry, and spatial relations within a unified framework and captures relational spatial structure beyond proximity alone, enabling rich contextualized representations across heterogeneous geoentities of points, polylines, and polygons. Evaluation on building function classification, traffic speed prediction, and next point-of-interest recommendation shows consistent improvements over prior methods, highlighting the benefit of unified relational modeling for vector geospatial data.
TiCLS : Tightly Coupled Language Text Spotter
Feb 03, 2026Scene text spotting aims to detect and recognize text in real-world images, where instances are often short, fragmented, or visually ambiguous. Existing methods primarily rely on visual cues and implicitly capture local character dependencies, but they overlook the benefits of external linguistic knowledge. Prior attempts to integrate language models either adapt language modeling objectives without external knowledge or apply pretrained models that are misaligned with the word-level granularity of scene text. We propose TiCLS, an end-to-end text spotter that explicitly incorporates external linguistic knowledge from a character-level pretrained language model. TiCLS introduces a linguistic decoder that fuses visual and linguistic features, yet can be initialized by a pretrained language model, enabling robust recognition of ambiguous or fragmented text. Experiments on ICDAR 2015 and Total-Text demonstrate that TiCLS achieves state-of-the-art performance, validating the effectiveness of PLM-guided linguistic integration for scene text spotting.
OMNI-Dent: Towards an Accessible and Explainable AI Framework for Automated Dental Diagnosis
Feb 03, 2026Accurate dental diagnosis is essential for oral healthcare, yet many individuals lack access to timely professional evaluation. Existing AI-based methods primarily treat diagnosis as a visual pattern recognition task and do not reflect the structured clinical reasoning used by dental professionals. These approaches also require large amounts of expert-annotated data and often struggle to generalize across diverse real-world imaging conditions. To address these limitations, we present OMNI-Dent, a data-efficient and explainable diagnostic framework that incorporates clinical reasoning principles into a Vision-Language Model (VLM)-based pipeline. The framework operates on multi-view smartphone photographs,embeds diagnostic heuristics from dental experts, and guides a general-purpose VLM to perform tooth-level evaluation without dental-specific fine-tuning of the VLM. By utilizing the VLM's existing visual-linguistic capabilities, OMNI-Dent aims to support diagnostic assessment in settings where curated clinical imaging is unavailable. Designed as an early-stage assistive tool, OMNI-Dent helps users identify potential abnormalities and determine when professional evaluation may be needed, offering a practical option for individuals with limited access to in-person care.
FRIEDA: Benchmarking Multi-Step Cartographic Reasoning in Vision-Language Models
Dec 08, 2025Cartographic reasoning is the skill of interpreting geographic relationships by aligning legends, map scales, compass directions, map texts, and geometries across one or more map images. Although essential as a concrete cognitive capability and for critical tasks such as disaster response and urban planning, it remains largely unevaluated. Building on progress in chart and infographic understanding, recent large vision language model studies on map visual question-answering often treat maps as a special case of charts. In contrast, map VQA demands comprehension of layered symbology (e.g., symbols, geometries, and text labels) as well as spatial relations tied to orientation and distance that often span multiple maps and are not captured by chart-style evaluations. To address this gap, we introduce FRIEDA, a benchmark for testing complex open-ended cartographic reasoning in LVLMs. FRIEDA sources real map images from documents and reports in various domains and geographical areas. Following classifications in Geographic Information System (GIS) literature, FRIEDA targets all three categories of spatial relations: topological (border, equal, intersect, within), metric (distance), and directional (orientation). All questions require multi-step inference, and many require cross-map grounding and reasoning. We evaluate eleven state-of-the-art LVLMs under two settings: (1) the direct setting, where we provide the maps relevant to the question, and (2) the contextual setting, where the model may have to identify the maps relevant to the question before reasoning. Even the strongest models, Gemini-2.5-Pro and GPT-5-Think, achieve only 38.20% and 37.20% accuracy, respectively, far below human performance of 84.87%. These results reveal a persistent gap in multi-step cartographic reasoning, positioning FRIEDA as a rigorous benchmark to drive progress on spatial intelligence in LVLMs.
Transit for All: Mapping Equitable Bike2Subway Connection using Region Representation Learning
Jun 18, 2025



Ensuring equitable public transit access remains challenging, particularly in densely populated cities like New York City (NYC), where low-income and minority communities often face limited transit accessibility. Bike-sharing systems (BSS) can bridge these equity gaps by providing affordable first- and last-mile connections. However, strategically expanding BSS into underserved neighborhoods is difficult due to uncertain bike-sharing demand at newly planned ("cold-start") station locations and limitations in traditional accessibility metrics that may overlook realistic bike usage potential. We introduce Transit for All (TFA), a spatial computing framework designed to guide the equitable expansion of BSS through three components: (1) spatially-informed bike-sharing demand prediction at cold-start stations using region representation learning that integrates multimodal geospatial data, (2) comprehensive transit accessibility assessment leveraging our novel weighted Public Transport Accessibility Level (wPTAL) by combining predicted bike-sharing demand with conventional transit accessibility metrics, and (3) strategic recommendations for new bike station placements that consider potential ridership and equity enhancement. Using NYC as a case study, we identify transit accessibility gaps that disproportionately impact low-income and minority communities in historically underserved neighborhoods. Our results show that strategically placing new stations guided by wPTAL notably reduces disparities in transit access related to economic and demographic factors. From our study, we demonstrate that TFA provides practical guidance for urban planners to promote equitable transit and enhance the quality of life in underserved urban communities.
StreetLens: Enabling Human-Centered AI Agents for Neighborhood Assessment from Street View Imagery
Jun 17, 2025Traditionally, neighborhood studies have employed interviews, surveys, and manual image annotation guided by detailed protocols to identify environmental characteristics, including physical disorder, decay, street safety, and sociocultural symbols, and to examine their impact on developmental and health outcomes. While these methods yield rich insights, they are time-consuming and require intensive expert intervention. Recent technological advances, including vision-language models (VLMs), have begun to automate parts of this process; however, existing efforts are often ad hoc and lack adaptability across research designs and geographic contexts. In this demo paper, we present StreetLens, a human-centered, researcher-configurable workflow that embeds relevant social science expertise in a VLM for scalable neighborhood environmental assessments. StreetLens mimics the process of trained human coders by grounding the analysis in questions derived from established interview protocols, retrieving relevant street view imagery (SVI), and generating a wide spectrum of semantic annotations from objective features (e.g., the number of cars) to subjective perceptions (e.g., the sense of disorder in an image). By enabling researchers to define the VLM's role through domain-informed prompting, StreetLens places domain knowledge at the core of the analysis process. It also supports the integration of prior survey data to enhance robustness and expand the range of characteristics assessed across diverse settings. We provide a Google Colab notebook to make StreetLens accessible and extensible for researchers working with public or custom SVI datasets. StreetLens represents a shift toward flexible, agentic AI systems that work closely with researchers to accelerate and scale neighborhood studies.
Hyper-Local Deformable Transformers for Text Spotting on Historical Maps
Jun 17, 2025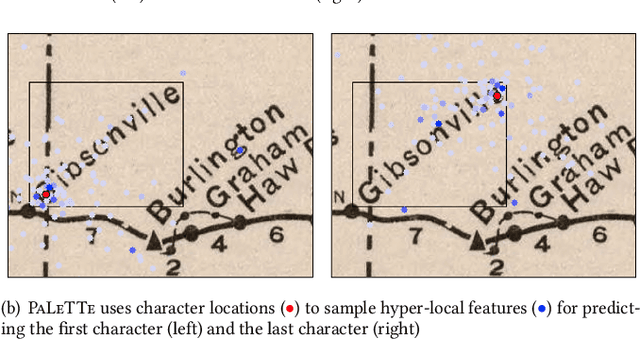
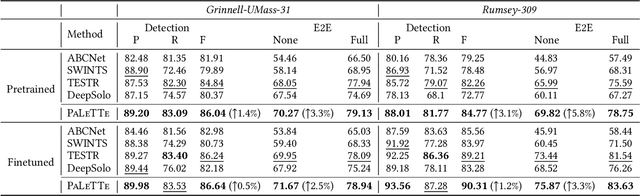

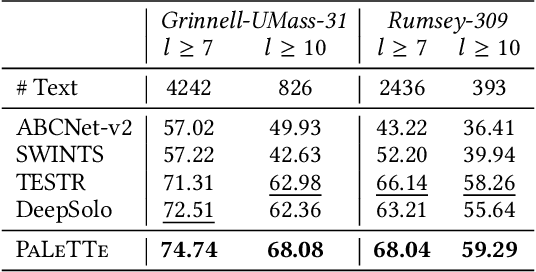
Text on historical maps contains valuable information providing georeferenced historical, political, and cultural contexts. However, text extraction from historical maps is challenging due to the lack of (1) effective methods and (2) training data. Previous approaches use ad-hoc steps tailored to only specific map styles. Recent machine learning-based text spotters (e.g., for scene images) have the potential to solve these challenges because of their flexibility in supporting various types of text instances. However, these methods remain challenges in extracting precise image features for predicting every sub-component (boundary points and characters) in a text instance. This is critical because map text can be lengthy and highly rotated with complex backgrounds, posing difficulties in detecting relevant image features from a rough text region. This paper proposes PALETTE, an end-to-end text spotter for scanned historical maps of a wide variety. PALETTE introduces a novel hyper-local sampling module to explicitly learn localized image features around the target boundary points and characters of a text instance for detection and recognition. PALETTE also enables hyper-local positional embeddings to learn spatial interactions between boundary points and characters within and across text instances. In addition, this paper presents a novel approach to automatically generate synthetic map images, SynthMap+, for training text spotters for historical maps. The experiment shows that PALETTE with SynthMap+ outperforms SOTA text spotters on two new benchmark datasets of historical maps, particularly for long and angled text. We have deployed PALETTE with SynthMap+ to process over 60,000 maps in the David Rumsey Historical Map collection and generated over 100 million text labels to support map searching. The project is released at https://github.com/kartta-foundation/mapkurator-palette-doc.
MapQA: Open-domain Geospatial Question Answering on Map Data
Mar 10, 2025Geospatial question answering (QA) is a fundamental task in navigation and point of interest (POI) searches. While existing geospatial QA datasets exist, they are limited in both scale and diversity, often relying solely on textual descriptions of geo-entities without considering their geometries. A major challenge in scaling geospatial QA datasets for reasoning lies in the complexity of geospatial relationships, which require integrating spatial structures, topological dependencies, and multi-hop reasoning capabilities that most text-based QA datasets lack. To address these limitations, we introduce MapQA, a novel dataset that not only provides question-answer pairs but also includes the geometries of geo-entities referenced in the questions. MapQA is constructed using SQL query templates to extract question-answer pairs from OpenStreetMap (OSM) for two study regions: Southern California and Illinois. It consists of 3,154 QA pairs spanning nine question types that require geospatial reasoning, such as neighborhood inference and geo-entity type identification. Compared to existing datasets, MapQA expands both the number and diversity of geospatial question types. We explore two approaches to tackle this challenge: (1) a retrieval-based language model that ranks candidate geo-entities by embedding similarity, and (2) a large language model (LLM) that generates SQL queries from natural language questions and geo-entity attributes, which are then executed against an OSM database. Our findings indicate that retrieval-based methods effectively capture concepts like closeness and direction but struggle with questions that require explicit computations (e.g., distance calculations). LLMs (e.g., GPT and Gemini) excel at generating SQL queries for one-hop reasoning but face challenges with multi-hop reasoning, highlighting a key bottleneck in advancing geospatial QA systems.
MiTREE: Multi-input Transformer Ecoregion Encoder for Species Distribution Modelling
Dec 25, 2024Climate change poses an extreme threat to biodiversity, making it imperative to efficiently model the geographical range of different species. The availability of large-scale remote sensing images and environmental data has facilitated the use of machine learning in Species Distribution Models (SDMs), which aim to predict the presence of a species at any given location. Traditional SDMs, reliant on expert observation, are labor-intensive, but advancements in remote sensing and citizen science data have facilitated machine learning approaches to SDM development. However, these models often struggle with leveraging spatial relationships between different inputs -- for instance, learning how climate data should inform the data present in satellite imagery -- without upsampling or distorting the original inputs. Additionally, location information and ecological characteristics at a location play a crucial role in predicting species distribution models, but these aspects have not yet been incorporated into state-of-the-art approaches. In this work, we introduce MiTREE: a multi-input Vision-Transformer-based model with an ecoregion encoder. MiTREE computes spatial cross-modal relationships without upsampling as well as integrates location and ecological context. We evaluate our model on the SatBird Summer and Winter datasets, the goal of which is to predict bird species encounter rates, and we find that our approach improves upon state-of-the-art baselines.